吾爱的大佬写的一个python文件
原文链接:https://www.52pojie.cn/forum.php?mod=viewthread&tid=2043136&extra=page%3D1&page=1
使用之前需要检查依赖:(可能需要科学)
- 检查pip:pip –version
- 升级pip: python -m pip install –upgrade pip
- 安装requests: pip install requests
- 安装beautifulsoup4: pip install beautifulsoup4
- 安装PySide6: pip install PySide6
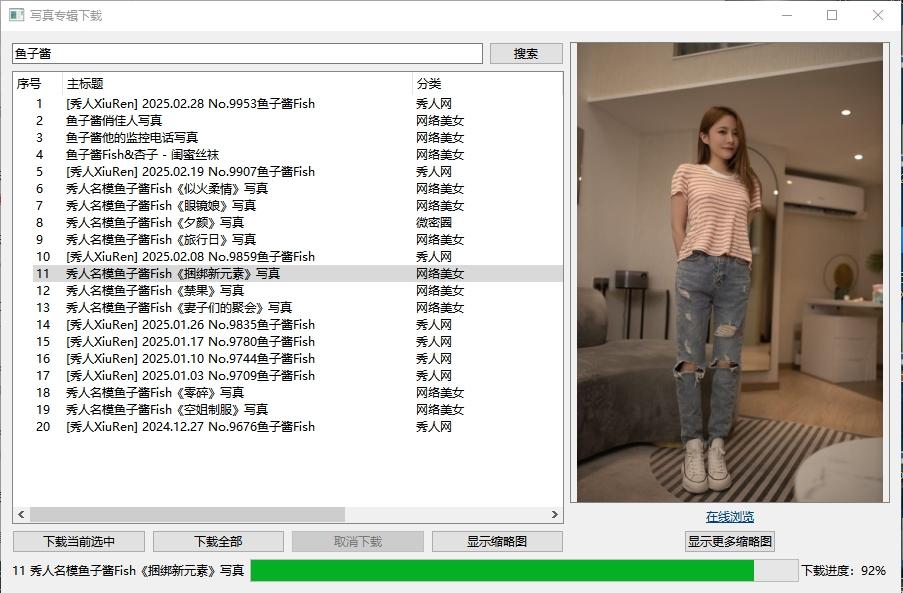
将大佬的python代码复制到txt文档,修改后缀为.py,然后运行。
实测很好用。
(有留言说chi du有点大,把网址隐藏了。主要学习技术如果你有朋友想看,去52看看吧)
import sys
import threading
import requests
from bs4 import BeautifulSoup
import re
import os
import html
from collections import deque
import time
import random
from PySide6.QtCore import QThread, Signal
from typing import List, Dict
from urllib.parse import urljoin
from PySide6.QtWidgets import (
QApplication, QWidget, QVBoxLayout, QHBoxLayout,
QLineEdit, QPushButton, QTreeWidget, QTreeWidgetItem,
QMessageBox, QLabel, QSizePolicy, QDialog,
QScrollArea, QGridLayout
)
from PySide6.QtWidgets import QProgressBar
from PySide6.QtGui import QPixmap
from PySide6.QtCore import Qt, QThread, QUrl, QSize
from PySide6.QtNetwork import QNetworkAccessManager, QNetworkRequest
from PySide6.QtCore import Qt, QByteArray
import logging
from urllib.parse import urlparse, urlunparse
# Configure logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 常量
BASE_URL = "https://www.×××××.cc"
def submit_search(keywords: str) -> str:
"""
提交搜索请求,返回重定向后的 URL
"""
form_data = {
"keyboard": keywords,
"show": "title",
"tempid": "1",
"tbname": "news"
}
SEARCH_URL = f"{BASE_URL}/e/search/index.php"
session = requests.Session()
response = session.post(SEARCH_URL, data=form_data, allow_redirects=False)
if response.status_code == 302:
new_location = response.headers.get("Location")
return urljoin(SEARCH_URL, new_location)
else:
print("未发生重定向,状态码:", response.status_code)
return ""
def get_total_count(soup: BeautifulSoup) -> int:
"""
从页面中提取总图片组数
"""
biaoqian_div = soup.find("div", class_="biaoqian")
if biaoqian_div:
p_text = biaoqian_div.find("p").get_text(strip=True)
match = re.search(r"(\d+)", p_text)
if match:
return int(match.group(1))
return 0
def parse_gallery_items_from_root(soup: BeautifulSoup) -> List[Dict[str, str]]:
"""
提取页面中所有图片组信息
"""
gallery_root = soup.find("div", class_="box galleryList")
items = []
if not gallery_root:
return items
for li in gallery_root.select("ul.databox > li"):
img_tag = li.select_one("div.img-box img")
ztitle_tag = li.select_one("p.ztitle a")
rtitle_tag = li.select_one("p.rtitle a")
author_tag = li.select_one("p.ztitle font")
# 1. 找到所有 class 为 img-box 的 div
count_tag = li.select_one("em.num")
href = ztitle_tag["href"] if ztitle_tag and ztitle_tag.has_attr("href") else ""
full_link = urljoin(BASE_URL, href)
count = 0
if count_tag:
text = count_tag.get_text(strip=True) # '15P'
match = re.search(r'\d+', text)
if match:
count = int(match.group(0))
# print(f"图集图片数量: {count}")
rtitle = rtitle_tag.get_text(strip=True) if rtitle_tag else ""
if author_tag:
author = author_tag.get_text(strip=True)
else:
author = rtitle
item = {
"img": img_tag["src"] if img_tag else "",
"ztitle": ztitle_tag.get_text(strip=True) if ztitle_tag else "",
"ztitle_href": full_link,
"author": author,
"rtitle": rtitle,
"count":str(count)
}
items.append(item)
return items
def crawl_single_gallery(url) -> List[Dict[str, str]]:
"""
提取当前单页面信息
"""
items = []
try:
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
# 判断是否存在 id="tishi" 的 div
tishi_div = soup.find('div', id='tishi')
if tishi_div:
# 未登陆情况下
# 提取提示中说的“全本XX张图片”
total_text = tishi_div.find('p').get_text() if tishi_div else ''
match = re.search(r'全本(\d+)张图片', total_text)
if match:
total_count = int(match.group(1))
#print(f"全图集共有 {total_count} 张图片")
else:
# 登陆情况下,默认本程序是不登陆的
# 从 id="page" 开始找
page_div = soup.find('div', id='page')
# 在 page_div 下找 span 含 "1/97" 结构
if page_div:
span = page_div.find('span', string=re.compile(r'\d+/\d+'))
if span:
match = re.search(r'\d+/(\d+)', span.text)
if match:
total_count = int(match.group(1))
print("总页数为:", total_count)
else:
print("未匹配到页码格式。")
else:
print("未找到包含页码的 <span> 标签。")
else:
print("未找到 id='page' 的 div。")
# 获取 gallerypic 区域
gallery_div = soup.find('div', class_='gallerypic')
if not gallery_div:
return items
# 获取 class 为 gallery_jieshao 的 div
jieshao_div = soup.find('div', class_='gallery_jieshao')
# 从中提取 h1 的内容
if jieshao_div:
title = jieshao_div.find('h1').get_text(strip=True)
#print("图集标题:", title)
type_author = [a.get_text(strip=True) for a in soup.select('.gallery_renwu_title a')]
first_img = gallery_div.find('img')
# if first_img and first_img.has_attr('src'):
# print("第一个图片地址:", first_img['src'])
# else:
# print("未找到 img 标签")
item = {
"img": first_img["src"] if first_img else "",
"ztitle": title,
"ztitle_href": url,
"author": type_author[1],
"rtitle": type_author[0],
"count":str(total_count)
}
items.append(item)
return items
except Exception as e:
result = "请求失败:" + str(e)
print(result)
return items
def crawl_all_pages(search_url: str) -> List[Dict[str, str]]:
"""
分页抓取所有图片组信息
"""
all_results = []
page = 0
if "searchid" in search_url:
searchid_match = re.search(r"searchid=(\d+)", search_url)
if not searchid_match:
print("无法提取 searchid")
return []
searchid = searchid_match.group(1)
while True:
# 构造分页 URL
if page == 0:
page_url = search_url
else:
page_url = f"{BASE_URL}/e/search/result/index.php?page={page}&searchid={searchid}"
print(f"\n[抓取第 {page + 1} 页] {page_url}")
try:
response = requests.get(page_url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
except Exception as e:
print("请求失败:", e)
break
if page == 0:
total = get_total_count(soup)
print(f"[总计] 页面声明图片组总数: {total}")
results = parse_gallery_items_from_root(soup)
if not results:
print("[结束] 当前页无数据,提前结束。")
break
all_results.extend(results)
# 打印当前页的结果
#for i, item in enumerate(results, 1):
# print(f" 第 {len(all_results) - len(results) + i} 项:")
# print(f" 缩略图: {item['img']}")
# print(f" 主标题: {item['ztitle']}")
# print(f" 分类 : {item['rtitle']}")
# print(f" 链接 : {item['ztitle_href']}")
#
if len(all_results) >= total:
print("[完成] 已抓取全部项目。")
break
page += 1
return all_results
else:
search_url = re.sub(r'_\d+\.html$', '.html', search_url)
response = requests.get(search_url)
if not response:
return "", []
soup = BeautifulSoup(response.text, "html.parser")
# 获取总页数
page_div = soup.find("div", class_="layui-box layui-laypage layui-laypage-default")
total_pages = 1
if page_div:
span = page_div.find("span")
if span:
match = re.search(r'\d+/(\d+)', span.text.strip())
if match:
total_pages = int(match.group(1))
print(f"总页数:{total_pages}")
for index in range(1,total_pages+1):
page_url = re.sub(r'\.html$', f'_{index}.html', search_url)
print(f"\n[抓取第 {index + 1} 页] {page_url}")
try:
response = requests.get(page_url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
except Exception as e:
print("请求失败:", e)
break
results = parse_gallery_items_from_root(soup)
if not results:
print("[结束] 当前页无数据,提前结束。")
break
all_results.extend(results)
return all_results
# --- PySide6 GUI ---
class GalleryCrawler(QWidget):
def __init__(self, cookies=None):
super().__init__()
self.setWindowTitle("写真专辑下载")
self.resize(900, 600)
self.init_ui()
self.download_queue = deque()
self.current_worker = None
self.cancel_requested = False
self.selected_items = None
self.is_downloading = False
self.cookies = cookies
self.headers = self._default_headers()
self.session = requests.Session()
self.session.headers.update(self.headers)
if cookies:
self.session.cookies.update(cookies)
def init_ui(self):
layout = QVBoxLayout(self)
main_layout = QHBoxLayout() # 水平主布局
# 左侧竖直布局(搜索条 + TreeView + 按钮)
left_layout = QVBoxLayout()
search_layout = QHBoxLayout()
self.search_input = QLineEdit()
self.search_input.setPlaceholderText("输入关键词搜索或直接粘贴网址...")
self.search_input.setText("")
self.search_btn = QPushButton("搜索")
self.search_btn.clicked.connect(self.start_search)
search_layout.addWidget(self.search_input)
search_layout.addWidget(self.search_btn)
self.tree = QTreeWidget()
self.tree.setHeaderLabels(["序号", "主标题", "分类", "链接","数量","作者"])
self.tree.setColumnWidth(0, 50)
self.tree.setColumnWidth(1, 350)
self.tree.setColumnWidth(2, 150)
self.tree.setColumnWidth(3, 300)
self.tree.setColumnWidth(4, 50)
self.tree.setColumnHidden(5, True)
self.tree.itemSelectionChanged.connect(self.on_tree_selection_changed) # 监听选中变化
btn_layout = QHBoxLayout()
self.btn_download_selected = QPushButton("下载当前选中")
self.btn_download_selected.clicked.connect(self.download_selected)
self.btn_download_all = QPushButton("下载全部")
self.btn_download_all.clicked.connect(self.download_all)
self.btn_cancel_download = QPushButton("取消下载")
self.btn_cancel_download.clicked.connect(self.cancel_download)
self.btn_cancel_download.setEnabled(False) # 初始禁用
self.btn_show_all_more = QPushButton("显示缩略图")
self.btn_show_all_more.clicked.connect(self.show_allthumbnails)
btn_layout.addWidget(self.btn_download_selected)
btn_layout.addWidget(self.btn_download_all)
btn_layout.addWidget(self.btn_cancel_download)
btn_layout.addWidget(self.btn_show_all_more)
left_layout.addLayout(search_layout)
left_layout.addWidget(self.tree)
left_layout.addLayout(btn_layout)
right_layout = QVBoxLayout()
# 右侧显示缩略图
self.image_label = QLabel("选中项缩略图显示区域")
self.image_label.setAlignment(Qt.AlignCenter)
self.image_label.setMinimumWidth(320)
self.image_label.setStyleSheet("border: 1px solid gray;")
self.link_label = QLabel()
self.link_label.setText('<a href="https://www.*******.cc/">在线浏览</a>')
self.link_label.setOpenExternalLinks(True) # ✅ 允许打开外部链接
self.link_label.setTextInteractionFlags(Qt.TextBrowserInteraction) # 可点击
self.link_label.setAlignment(Qt.AlignCenter)
# 显示更多按钮
self.btn_show_more = QPushButton("显示更多缩略图")
self.btn_show_more.clicked.connect(self.show_thumbnails)
self.btn_show_more.setSizePolicy(QSizePolicy.Fixed, QSizePolicy.Preferred)
right_layout.addWidget(self.image_label, stretch=1)
right_layout.addWidget(self.link_label, stretch=0)
right_layout.addWidget(self.btn_show_more, stretch=0, alignment=Qt.AlignHCenter)
# 底部添加进度条
bottom_layout = QHBoxLayout()
self.album_label = QLabel()
self.album_label.setText('')
self.progress_bar = QProgressBar()
self.progress_bar.setMinimum(0)
self.progress_bar.setMaximum(100)
self.progress_bar.setValue(0)
self.progress_bar.setTextVisible(True)
self.progress_bar.setFormat("下载进度:%p%")
bottom_layout.addWidget(self.album_label, stretch=0)
bottom_layout.addWidget(self.progress_bar, stretch=1)
# 添加左右布局
main_layout.addLayout(left_layout, 3) # 左边占3份
main_layout.addLayout(right_layout, 1) # 右边占1份
layout.addLayout(main_layout)
# 此处添加进度条
layout.addLayout(bottom_layout)
def _default_headers(self):
"""Default headers to mimic browser behavior"""
return {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "max-age=0",
"sec-ch-ua": '"Google Chrome";v="137", "Chromium";v="137", "Not/A)Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36",
}
def show_allthumbnails(self):
img_list = []
for i in range(self.tree.topLevelItemCount()):
item = self.tree.topLevelItem(i)
img = item.data(0, Qt.ItemDataRole.UserRole + 1)
if img:
img_list.append(img)
# 去重并保留顺序
img_urls = list(dict.fromkeys(img_list))
if len(img_urls) == 0:
QMessageBox.warning(self, "提示", "请先搜索")
return
# 创建实例
worker = DownloadWorker(self.session, "", "", img_urls, 0)
dialog = ThumbnailViewer(img_urls, self)
dialog.exec()
def show_thumbnails(self):
selected_item = self.tree.currentItem()
if selected_item is None:
QMessageBox.warning(self, "提示", "请先选择一项")
return
img_url = selected_item.data(0, Qt.ItemDataRole.UserRole + 1)
album_index = selected_item.text(0)
album_title = selected_item.text(1)
img_url = selected_item.text(3)
total_count = int(selected_item.text(4))
author = selected_item.text(5)
# 创建实例
worker = DownloadWorker(self.session, author, album_title, img_url, total_count)
# 调用方法获取图片链接
image_urls = worker.get_image_urls()
dialog = ThumbnailViewer(image_urls, self)
dialog.exec()
def cancel_download(self):
self.cancel_requested = True
self.download_queue.clear() # 清除后续任务
if self.current_worker and self.current_worker.isRunning():
self.current_worker.terminate() # 强行终止当前线程(⚠️ 不推荐用于长期任务)
self.current_worker.wait()
self.progress_bar.setValue(0)
self.is_downloading = False
self.btn_cancel_download.setEnabled(False)
self.btn_download_all.setEnabled(True)
self.search_btn.setEnabled(True)
self.enable_search()
QMessageBox.information(self, "提示", "下载任务已被取消。")
self.set_album("")
def set_album(self, value:str):
def update():
self.album_label.setText(value)
self.run_on_main_thread(update)
def set_progress(self, value: int):
def update():
self.progress_bar.setValue(value)
self.run_on_main_thread(update)
def on_tree_selection_changed(self):
selected_items = self.tree.selectedItems()
if not selected_items:
self.image_label.setText("选中项缩略图显示区域")
self.image_label.setPixmap(QPixmap()) # 清空图片
self.link_label.setText('<a href="https://www.*******.cc/">在线浏览</a>')
return
item = selected_items[0]
img_url = item.data(0, Qt.ItemDataRole.UserRole + 1)
album_index = item.text(0)
album_title = item.text(1)
if not self.is_downloading:
self.set_album(album_index + " " + album_title)
self.set_progress(0)
if not img_url:
self.image_label.setText("无缩略图")
self.image_label.setPixmap(QPixmap())
self.link_label.setText('<a href="https://www.*******.cc/">在线浏览</a>')
return
self.link_label.setText(f'<a href="{item.text(3)}">在线浏览</a>')
# 异步加载图片避免卡界面
threading.Thread(target=self.load_image_from_url, args=(img_url,), daemon=True).start()
def load_image_from_url(self, url):
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
data = response.content
except Exception:
self.run_on_main_thread(lambda: self.image_label.setText("加载图片失败"))
return
pixmap = QPixmap()
pixmap.loadFromData(data)
scaled = pixmap.scaled(self.image_label.size(), Qt.AspectRatioMode.KeepAspectRatio, Qt.TransformationMode.SmoothTransformation)
def set_pix():
self.image_label.setPixmap(scaled)
self.image_label.setText("")
self.run_on_main_thread(set_pix)
def start_search(self):
keyword = self.search_input.text().strip()
if not keyword:
QMessageBox.warning(self, "提示", "请输入关键词!")
return
if keyword.startswith("https://www.*******.cc") and "searchid" not in keyword and "/gallery" not in keyword:
threading.Thread(target=self.search_by_url, args=(keyword,), daemon=True).start()
elif keyword.startswith("https://www.*******.cc") and "/gallery" in keyword:
threading.Thread(target=self.search_by_gallery, args=(keyword,), daemon=True).start()
else:
threading.Thread(target=self.search_and_load, args=(keyword,), daemon=True).start()
self.search_btn.setEnabled(False)
self.tree.clear()
self.set_album("")
self.set_progress(0)
self.selected_items = None
self.image_label.setText("选中项缩略图显示区域")
def search_by_gallery(self,search_url):
results = crawl_single_gallery(search_url)
if not results:
self.show_message("未找到任何结果。")
self.enable_search()
return
self.load_results(results)
self.enable_search()
def search_and_load(self, keyword):
search_url = submit_search(keyword)
if not search_url:
self.show_message("搜索失败,未获取有效跳转链接。")
self.enable_search()
return
self.search_by_url(search_url)
def search_by_url(self,search_url):
results = crawl_all_pages(search_url)
if not results:
self.show_message("未找到任何结果。")
self.enable_search()
return
self.load_results(results)
self.enable_search()
def load_results(self, results):
def update_ui():
self.tree.clear()
for idx, item in enumerate(results, 1):
tree_item = QTreeWidgetItem([
str(idx),
item["ztitle"],
item["rtitle"],
item["ztitle_href"],
item["count"],
item["author"]
])
tree_item.setData(0, Qt.ItemDataRole.UserRole + 1, item["img"])
self.tree.addTopLevelItem(tree_item)
self.run_on_main_thread(update_ui)
def download_selected(self):
if self.is_downloading:
QMessageBox.information(self, "提示", "当前任务正在下载中,请等待完成。")
return
items = self.tree.selectedItems()
if not items:
QMessageBox.information(self, "提示", "请先选中要下载的项。")
return
album_index = items[0].text(0)
album_title = items[0].text(1)
download_url = items[0].text(3)
total_count = int(items[0].text(4))
author = items[0].text(5)
self.is_downloading = True
self.progress_bar.setValue(0)
self.set_album(album_index + " " + album_title)
self.worker = DownloadWorker(self.session, author, album_title, download_url, total_count)
self.worker.progress.connect(self.set_progress)
def finish_handler(msg):
QMessageBox.information(self, "完成", msg)
self.is_downloading = False
self.btn_download_selected.setEnabled(True)
self.btn_download_all.setEnabled(True)
self.search_btn.setEnabled(True)
self.worker.finished.connect(finish_handler)
self.worker.message.connect(lambda err: QMessageBox.critical(self, "错误", err))
self.worker.start()
def download_all(self):
if self.is_downloading:
QMessageBox.information(self, "提示", "当前任务正在下载中,请等待完成。")
return
count = self.tree.topLevelItemCount()
if count == 0:
QMessageBox.information(self, "提示", "无数据可下载。")
return
self.download_queue.clear()
self.cancel_requested = False
self.btn_cancel_download.setEnabled(True)
self.btn_download_all.setEnabled(False)
self.search_btn.setEnabled(False)
for i in range(count):
item = self.tree.topLevelItem(i)
album_index = item.text(0)
album_title = item.text(1)
download_url = item.text(3)
total_count = int(item.text(4))
author = item.text(5)
self.download_queue.append((album_index,author, album_title, download_url, total_count))
self.progress_bar.setValue(0)
self.start_next_download()
def start_next_download(self):
if self.cancel_requested:
QMessageBox.information(self, "取消", "下载已取消。")
self.btn_cancel_download.setEnabled(False)
self.btn_download_all.setEnabled(True)
self.search_btn.setEnabled(True)
self.enable_search()
return
if not self.download_queue:
QMessageBox.information(self, "完成", "全部下载完成!")
self.is_downloading = False
self.btn_cancel_download.setEnabled(False)
self.btn_download_all.setEnabled(True)
self.search_btn.setEnabled(True)
self.enable_search()
return
album_index,author, album_title, url, total_count = self.download_queue.popleft()
self.progress_bar.setValue(0)
self.set_album(album_index + " " + album_title)
self.current_worker = DownloadWorker(self.session, author, album_title, url, total_count)
self.current_worker.progress.connect(self.set_progress)
self.current_worker.message.connect(lambda err: QMessageBox.critical(self, "错误", err))
def on_finished(msg):
logger.info(msg)
self.start_next_download()
self.current_worker.finished.connect(on_finished)
self.current_worker.start()
def show_message(self, text):
def msg():
QMessageBox.information(self, "提示", text)
self.run_on_main_thread(msg)
def enable_search(self):
def en():
self.search_btn.setEnabled(True)
self.run_on_main_thread(en)
def run_on_main_thread(self, func):
# PySide6 主线程调用
QApplication.instance().postEvent(self, _FuncEvent(func))
def customEvent(self, event):
event.func()
class DownloadWorker(QThread):
progress = Signal(int)
finished = Signal(str)
message = Signal(str)
def __init__(self, session, album_title, title, url,total_count):
super().__init__()
self.session = session
self.album_title = album_title
self.title = title
self.url = url
self.total_count = total_count
def run(self):
try:
success = self.process_album()
if success:
self.finished.emit(f"{self.title} 下载完成")
else:
self.finished.emit(f"{self.title} 下载失败")
except Exception as e:
self.message.emit(f"{self.title} 异常: {e}")
def safe_request(self, url, timeout=10):
try:
response = self.session.get(url, timeout=timeout)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response
except Exception:
return None
def download_image(self, url, filepath):
if os.path.exists(filepath):
return True
try:
response = self.session.get(url, timeout=15, stream=True)
response.raise_for_status()
os.makedirs(os.path.dirname(filepath), exist_ok=True)
with open(filepath, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
return True
except:
return False
def get_image_urls(self):
response = self.safe_request(self.url)
if not response:
return []
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.select("div.gallerypic img")
if not img_tags:
return []
first_img_url = img_tags[0].get("src", "")
# 提取扩展名(如 .jpg 或 .png)
ext_match = re.search(r'\.(jpg|png|jpeg|gif|webp)$', first_img_url, re.IGNORECASE)
extension = ext_match.group(0) if ext_match else ".jpg" # 默认.jpg
is_numbered = re.search(r"/(\d{3})\.[a-zA-Z]+$", first_img_url)
image_urls = []
parsed = urlparse(first_img_url)
base_path = os.path.dirname(parsed.path)
base_url = urlunparse((parsed.scheme, parsed.netloc, base_path, '', '', ''))
if is_numbered:
for i in range(1, self.total_count + 1):
img_url = f"{base_url}/{i:03d}{extension}"
image_urls.append(img_url)
else:
for i in range(0, self.total_count):
img_url = f"{base_url}/{i}{extension}"
image_urls.append(img_url)
return image_urls
def process_album(self):
image_urls = self.get_image_urls()
if not image_urls:
return False
album_dir = os.path.join(self.album_title, self.title) if self.album_title else self.title
os.makedirs(album_dir, exist_ok=True)
total_count = len(image_urls)
success_count = 0
for index, img_url in enumerate(image_urls):
# 保留原始扩展名,默认使用 .jpg
filename_from_url = os.path.basename(img_url)
# 拼接保存路径
filename = os.path.join(album_dir, filename_from_url)
if self.download_image(img_url, filename):
success_count += 1
self.progress.emit(int(success_count / total_count * 100))
return success_count > 0
from PySide6.QtCore import QEvent
class _FuncEvent(QEvent):
def __init__(self, func):
super().__init__(QEvent.Type.User)
self.func = func
class ThumbnailViewer(QDialog):
def __init__(self, image_urls, parent=None):
super().__init__(parent)
title = "缩略图预览 共" + str(len(image_urls)) + "张"
self.setWindowTitle(title)
self.resize(850, 600)
scroll = QScrollArea(self)
scroll.setWidgetResizable(True)
container = QWidget()
scroll.setWidget(container)
layout = QVBoxLayout(self)
layout.addWidget(scroll)
grid = QGridLayout(container)
self.nam = QNetworkAccessManager(self)
self.thumb_size = QSize(150, 250) # 缩略图大小
for i, url in enumerate(image_urls):
# 创建一个垂直容器,放图片和序号label
widget = QWidget()
v_layout = QVBoxLayout(widget)
v_layout.setContentsMargins(0, 0, 0, 0)
v_layout.setSpacing(2)
label = QLabel("加载中…")
label.setFixedSize(self.thumb_size)
label.setAlignment(Qt.AlignCenter)
label.setStyleSheet("border: 1px solid gray;")
number_label = QLabel(str(i + 1))
number_label.setAlignment(Qt.AlignCenter)
v_layout.addWidget(label)
v_layout.addWidget(number_label)
grid.addWidget(widget, i // 5, i % 5) # 每行5个
self.load_image_async(url, label)
def load_image_async(self, url, label):
request = QNetworkRequest(QUrl(url))
request.setAttribute(QNetworkRequest.Http2AllowedAttribute, False) # 禁用 HTTP/2
reply = self.nam.get(request)
def handle_finished():
pixmap = QPixmap()
if pixmap.loadFromData(reply.readAll()):
label.setPixmap(pixmap.scaled(
self.thumb_size, Qt.KeepAspectRatio, Qt.SmoothTransformation))
else:
label.setText("加载失败")
reply.deleteLater()
reply.finished.connect(handle_finished)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = GalleryCrawler()
window.show()
sys.exit(app.exec())